Transcriptions from Friend in Obsidian
I’ve been wearing a Friend / Omi (not to be confused with the other one) for a couple of weeks. This project is interesting to me because of the open-source component and community that it has. So I made my own, including it’s own case. One thing I’ve been trying to find a solution for has been trying to get all transcription into my note taking program Obsidian.
And I figured out a way to do this. Thanks to the wonderful val.town and Cloudflare R2 (or any S3 bucket compatible provider) it’s quite a chain of things, but it works! You start of with a val.town endpoint with the following code:
import { S3Client } from "https://deno.land/x/s3_lite_client@0.6.1/mod.ts";
const cloudflareR2client = new S3Client({
endPoint: Deno.env.get("cloudflareR2Endpoint"),// This stores as secrets in val.town
region: "auto",
bucket: Deno.env.get("cloudflareR2Bucket"), // This stores as secrets in val.town
accessKey: Deno.env.get("cloudflareR2Key"), // This stores as secrets in val.town
secretKey: Deno.env.get("cloudflareR2Secret"), // This stores as secrets in val.town
});
export default async function(req: Request): Promise<Response> {
let currentDate = new Date().toISOString(); // Otherwise, we take the current date
await cloudflareR2client.putObject("transcription-" + currentDate + ".json", req.body);
return Response.json({ ok: true });
}
Be sure to connect the Friend app with developer mode to the endpoint!
Now each transcription is stored into Cloudflare R2. I then use the S3 Files app on my mac to synchronize the R2 bucket. Hazel watches the synced folder and runs a little python script that converts each JSON file containing the transcription into markdown and creates a file in the target folder.
import glob
import datetime
import json
TRANSCRIPTION_JSON_DIR = "<transcription_dir>"
TRANSCRIPTION_MD_DIR = "<output dir>"
def convert_transcription_to_markdown(transcription_file):
created_at = datetime.datetime.fromisoformat(transcription_file.get("created_at"))
markdown_filename = created_at.isoformat().replace(":", "_").replace("T", "_")[0:19] + '.md'
structured_data = transcription_file.get("structured", {})
title = structured_data.get("title")
emoji = structured_data.get("emoji")
transcription_text = []
for segment in transcription_file['transcript_segments']:
if segment.get("text"):
transcription_text.append(segment.get("text"))
transcription = "\n - ".join(transcription_text)
# Feel free to modify this template to include more data, like the summary!
markdown_content = f"""---
created_at: {created_at.isoformat()}
title: {title}
---
# {emoji} {title}
- {transcription}
"""
return markdown_filename, markdown_content
def write_transcription_markdown_file(markdown_filename, markdown_content):
with open(TRANSCRIPTION_MD_DIR + markdown_filename, "w+") as markdown_file:
markdown_file.write(markdown_content)
for transcription_file in glob.glob(TRANSCRIPTION_JSON_DIR + '*.json'):
with open(transcription_file, 'r', encoding='utf-8') as transcription_content:
markdown_filename, markdown_content = convert_transcription_to_markdown(json.loads(transcription_content.read()))
print(f"Writing {markdown_filename}")
write_transcription_markdown_file(markdown_filename, markdown_content)
I then use dataview in my daily note in Obsidian too see all transcriptions for that day for example: TABLE title as Summary, created_at WHERE startswith(file.name, "<date>") and title SORT file.mtime ASC This results in the following table in Obsidian:
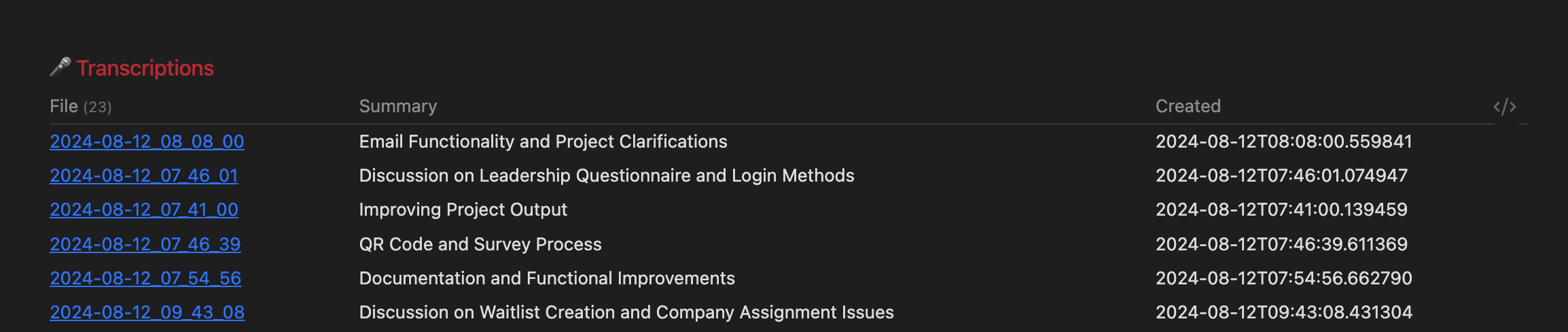
This is pretty awesome I think. Since I can now search through everything I spoke about, without taking notes at all! In future versions I might be able to get tasks from files and put reminders into future daily notes etc etc.. Think of the possibilities of having your own voice be an input of your PKM system!