Datavisualisatie voor het CBS
Het CBS organiseert de eerste seminar over interactieve data visualisaties op 3 februari in Den Haag. Voor de seminar is een wedstrijd gemaakt en ik had een vrije middag over om er mee aan de slag te gaan.
Nadat ik alle drie de data-sets heb bekeken leek het mij het beste om de derde (Landbouw; economische omvang naar omvangsklasse, hoofdbedrijfstype & regio) aan de slag te gaan. Nadat ik de data had gedownload heb ik eerst Google Refine gebruikt om de data schoon te maken en te filteren.
Ik werk graag met Raphael.js dus had in een uurtje al snel een prototype werkend waarbij op de kaart van Nederland per provincie het aantal stond met een cirkel. Al snel had ik het voor elkaar om ook het verloop van tijd in te bouwen. Allemaal leuk en aardig, maar je mist wel het inzicht. Zo kan je bijvoorbeeld moeilijk provincies met elkaar vergelijken als de cirkels even groot zijn, maar ze niet op dezelfde as staan:
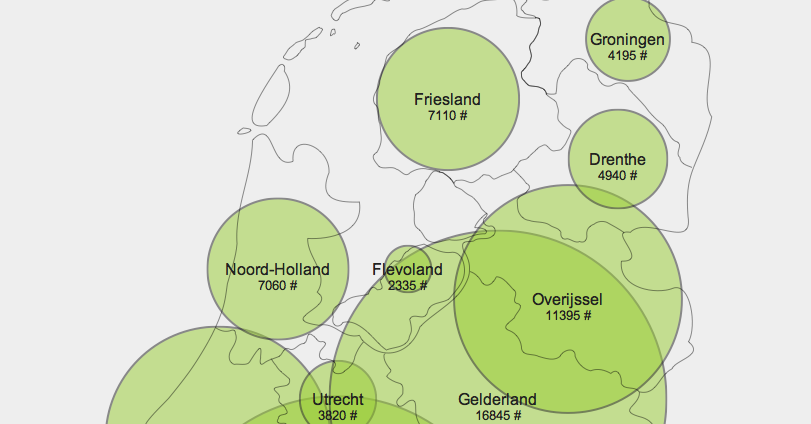
Om dat probleem op te lossen ben ik terug gestapt naar een eenvoudig staafdiagram. Zo kan je met behulp van beide visualisaties provincies vergelijken of kijken in welke delen van nederland het meeste tuinbouw is. Het switchen van visualisaties gaat gemakkelijk en alle ingevulde parameters blijven staan.
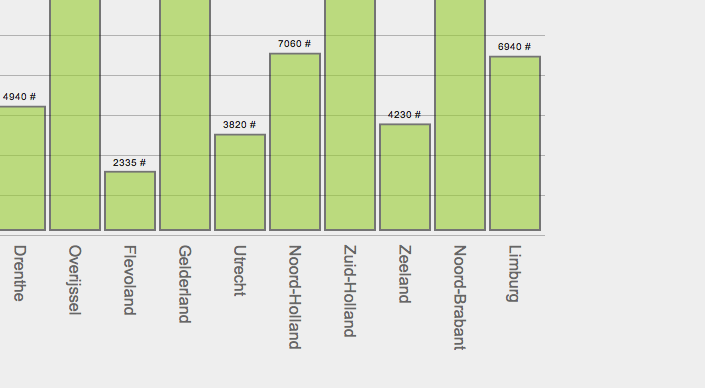
Om alles af te ronden heb ik ook alle getallen erin genoteerd zodat deze ook zijn af te lezen en heb ik een slider gebruikt als interface voor het verloop van tijd. Nog wat kleine stukjes css erbij en het is leuk genoeg geweest voor een vrije middag :-)
Als ik tijd over had zou ik de volgende dingen verbeteren:
- Overlappende cirkels insinueren een relatie, terwijl dit niet het geval is… Misschien is hier een oplossing voor door ervoor te zorgen dat dit niet gebeurd.
- De y-as van het staafdiagram bied nu geen extra informatie… Ik zou deze ook graag schaalbaar maken met de data die op dat moment te zien is.
- De play knop voor de tijd, zodat je kan zien hoe alles verloopt in plaats van met je muis te slepen.
- De granulatie van de data zorgt ervoor dat er weinig andere datasets aan te koppelen zijn zonder onbedoelde relaties te leggen.